资讯
近日消息,苹果研究团队最近在学术平台ArXiv上揭晓了题为《MM1:探索多模态LLM预训练方法、分析与洞见》的研究论文,文中详述了一款名为“MM1”的创新多模态深度学习框架。

该框架分别推出了规模涵盖30亿至300亿参数级别的多个版本模型,这些模型凭借其强大的图像解析和自然语言理解推理能力而引人注目。MM1大模型不仅标志着苹果公司在跨模态人工智能技术方面的重大突破,而且在图像与文本的深度融合及智能推理应用方面展现了前所未有的潜力。
苹果研究团队相关论文主要是利用 MM1 模型做实验,通过控制各种变量,找出影响模型效果的关键因素。
研究表明,图像分辨率和图像标记数量对模型性能影响较大,视觉语言连接器对模型的影响较小,不同类型的预训练数据对模型的性能有不同的影响。
据介绍,研究团队首先在模型架构决策和预训练数据上进行小规模消融实验。之后利用混合专家(Mixture of Experts)架构及一种名为 Top-2 Gating 的方法构建了 MM1 模型,号称不仅在预训练指标中实现了最好的性能表现,在一系列已有多模态基准上监督微调后也能保持有竞争力的性能。
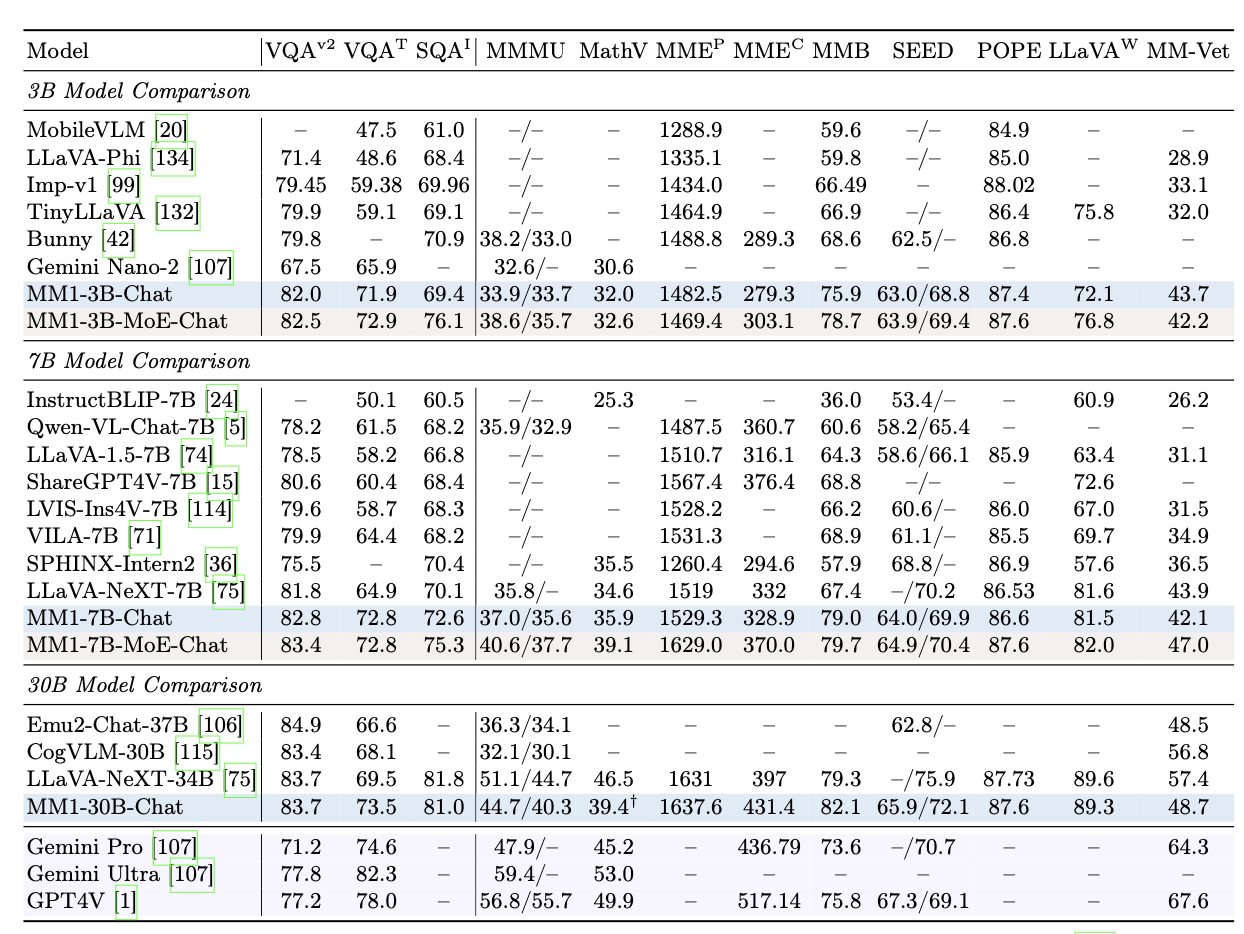
研究人员对“MM1”模型进行了测试,号称 MM1-3B-Chat 和 MM1-7B-Chat 优于市面上绝大多数相同规模的模型。
MM1-3B-Chat 和 MM1-7B-Chat 在 VQAv2、TextVQA、ScienceQA、MMBench、MMMU 和 MathVista 中表现尤为突出,但是整体表现不如谷歌的 Gemini 和 OpenAI 的 GPT-4V。










文明上网,理性发言,共同做网络文明传播者