资讯
近日消息,在人工智能这个充满无限可能的领域内,文本音频生成技术正稳步成为研究焦点所在。就在不久前,研究者们成功推出了一款被叫做TANGOFLUX的新型模型。这款模型无论是在性能表现方面,还是在效率高低上,都有着相当出色的发挥。
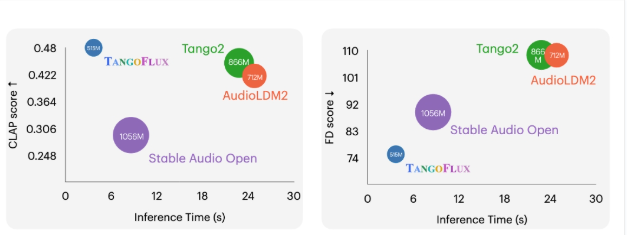
TANGOFLUX 是一种高效的文本到音频生成模型,拥有515百万个参数,能够在短短3.7秒内生成最长可达30秒的44.1kHz 音频,这一速度让其在单个 A40GPU 上的表现非常出色。
TANGOFLUX主要是特色是可以生成各种音效,例如鸟叫、口哨、爆炸等声音,另外也支持生成音乐不过效果就不那么理想了。
文本音频生成模型的一个主要挑战在于如何创建偏好配对。与大型语言模型(LLMs)不同,文本音频生成模型缺乏可验证的奖励机制或金标准答案。为了解决这个问题,研究团队提出了一种名为 CLAP-Ranked Preference Optimization(CRPO)的新框架。该框架通过迭代生成和优化偏好数据,以提升文本音频生成模型的对齐性能。研究表明,使用 CRPO 生成的音频偏好数据在性能上优于现有的替代方案。
通过这一框架,TANGOFLUX 在多项客观和主观基准测试中都取得了领先的表现。此外,研究团队还决定将所有代码和模型开源,以支持更多人对文本音频生成的研究。对于需要音频生成的应用场景,TANGOFLUX 无疑是一项具有重要意义的技术进展。
在实际效果方面,TANGOFLUX 在音频生成质量上优于其他模型,展现出更清晰的事件声音、更好的事件顺序再现以及更高的音频质量。通过对多个示例的比较,用户可以直观地感受到 TANGOFLUX 在音频生成中的优势。
随着这一新技术的问世,文本到音频生成的应用前景愈加广阔,未来可能会在影视制作、游戏音效等领域发挥重要作用。












文明上网,理性发言,共同做网络文明传播者