资讯
阿里巴巴在多模态模型研发领域再次取得重大进展,其自主研发的Qwen-VL模型已顺利完成升级并推出两个全新版本——Qwen-VL-Plus及Qwen-VL-Max。
这两个迭代版在处理文本与图像融合的多模态任务时展现出了卓越性能,其效果堪比业界领先的Gemini Ultra和GPT-4V等先进模型,在多项基准测试中均有出色表现。

此次更新不仅提升了模型的基础能力,更预示着阿里巴巴在人工智能跨模态理解与生成领域的技术探索已经达到了新的高度。
Qwen-VL-Max在中文问答和中文文本理解任务上超越了GPT-4V和Gemini,同时在图像相关推理能力和识别、提取和分析图像细节上都有显著提升。这两个版本还支持处理高达一百万像素的高清图像以及各种宽高比的图像。
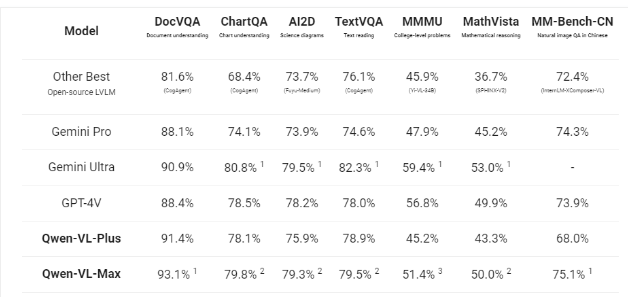
Qwen-VL-Plus针对细节识别和文本识别能力进行了显著升级,支持超高像素分辨率和任意宽高比的图像输入,在广泛的视觉任务上提供了显著的性能提升。
而Qwen-VL-Max则在视觉推理和指令跟随能力方面有所改进,提供了更高级别的视觉感知和认知理解,在更广泛的复杂任务上提供了最优性能。这两个版本甚至能识别Gif图,展现出了强大的识别能力。










文明上网,理性发言,共同做网络文明传播者