资讯
近日,Google Gemini 1.5版本带来了一项震撼业界的技术革新。此更新中,Google引入了一个前所未有的、能够处理高达一百万个令牌的超大规模上下文窗口机制。这项突破性的新功能,旨在全面应对并精准解析包含完整书籍、长篇文档乃至电影剧本等复杂内容场景,其核心聚焦在于对庞大数据信息进行高精度识别与理解。

通过该“百万令牌上下文窗口”功能,Gemini 1.5版本将深入挖掘并掌握更广阔的信息语境,无论是在长文本分析、剧情预测还是知识推理等方面均展现出显著提升的准确性,无疑为用户提供了更为强大和智能的内容处理能力。
尽管Gemini1.5的上下文窗口容量庞大,但可能仍存在不准确再现信息的可能性。在“海底捞针”测试中,该系统需要提取多达100条特定信息,但平均准确度仅在60%至70这项任务相对于复杂文档的摘要撰写而言仍然要简单一些。
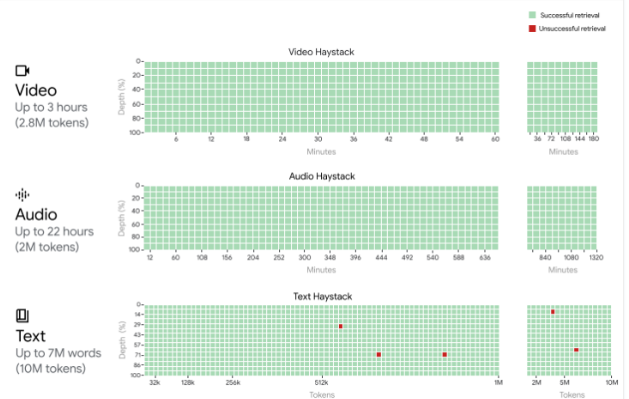
值得一提的是,在谷歌对维克多·雨果的《悲惨世界》进行的更复杂的测试中,他们提出了100个问题,共涉及710,000个标记,并使用“归因于已识别来源”的方法进行答案评估。结果显示,在人工评估中,80% 的答案可归因于源文档,而在机器评估中则有91% 的答案可归因于源文档。然而,这一基准倾向目前的权威及其与原著作者之间存在细微的差异。
在“大海捞针”测试中,模型必须在上下文窗口中找到一条信息。这与LLM的实际应用场景关系不大。
尽管社交媒体上对Gemini1.5的积极评价络并不绝,但即将对其准确性进行更深入的评估。大多数评论焦点于功能测试,缺乏对源材料的深入了解。如果信息检索的可信度不高,即使在复杂的查询下,巨大的上下文窗口可能仍然存在问题。
可见, Gemini1.5 Pro 提供了令人印象深刻的技术突破,但在实践中,提取复杂的信息仍然是一个挑战。如果其可靠性低于90%,那么实际中的巨大容量的上下文窗口运用中可能并不具备专业的帮助。











文明上网,理性发言,共同做网络文明传播者