资讯
7月5日消息,“数字甲骨共创中心”于今日正式将全球最大的甲骨文多模态数据集开源,其中总共涵盖了一万片甲骨的拓片、摹本,还包括甲骨单字对应的位置、对应的字头、对应的释文以及辞例分组、释读顺序等数据。
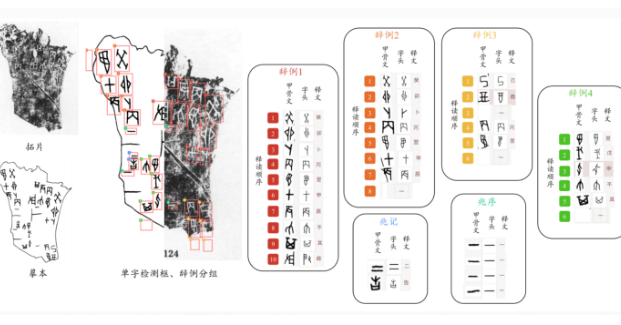
据介绍,所有研究者都能基于该数据集研发甲骨文检测、识别、摹本生成、字形匹配和释读等算法,加速甲骨文研究智能化进程。
数字甲骨共创中心由安阳师范学院甲骨文信息处理教育部实验室、腾讯 SSV 数字文化实验室、腾讯优图实验室、中国社会科学院甲骨学殷商史研究中心、中国社会科学院考古研究所安阳工作站、厦门大学多媒体可信感知与高效计算教育部重点实验室、郑州大学汉字文明研究中心等单位共同发起,并获得中国社会科学院古代史研究所、英国剑桥大学、法国高等研究实践学院、日本立命馆大学、美国罗格斯大学、加州大学洛杉矶分校等全球高校和研究机构的支持。
腾讯优图实验室、腾讯 SSV 数字文化实验室、厦门大学、安阳师范学院联合开发了 AI 模型技术:
甲骨字检测模型:标注准确率超 90%
摹本生成模型:摹本-拓片逐像素对齐
字形匹配模型:自动匹配相近字
甲骨校重模型:在大量拓片和摹本中实现“摹本去重”和“拓片探源”
全球最大甲骨文多模态数据集已在“甲骨文 AI 协同平台”上线,该平台还可以查询甲骨文、甲骨片信息,具体功能可以自行访问体验。












文明上网,理性发言,共同做网络文明传播者